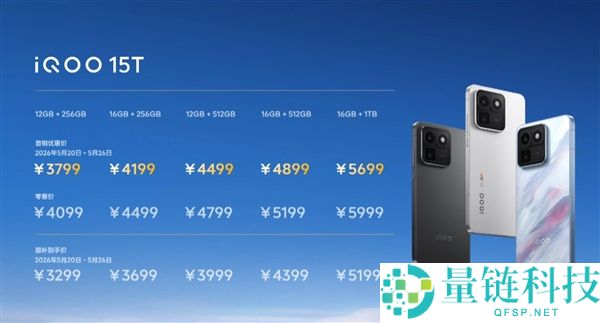
5 月 20 日消息:在 Google I/O 2026 上,谷歌正式发布 Gemini Omni 模型。该模型支持文本、图像、音频、视频作为输入,实现跨模态生成与编辑。
其中在音频方面,目前该模型初期仅支持语音输入,但Google表示未来将很快扩展更多类型的音频输入能力。
首发产品Gemini Omni Flash已在Gemini应用上线,后续将向企业客户开放API。
该模型核心卖点在于深度视频编辑能力。用户通过自然语言指令即可对生成内容持续迭代,包括添加或删除对象、切换摄像机角度、修改环境与风格。
得益于模型对物理规律的理解以及对历史、科学、文化知识的整合,生成的视频在角色、场景及视觉逻辑上高度连贯,甚至能推测后续情节。用户亦可创建个人数字分身,并将其植入视频中。
谷歌在安全领域同步布局,所有通过Omni生成的视频均会自动嵌入SynthID数字水印,支持通过Google搜索及Chrome验证。
Gemini Omni Flash 现已面向拥有 Google AI Plus/Pro/Ultra 订阅的用户在 Gemini 应用和 Google Flow 中推出。此外,它还免费向希望混剪 YouTube Shorts 的用户以及 YouTube Create 应用用户推出。
Google DeepMind负责人哈萨比斯表示,该模型正推动AI从单纯的任务执行向通用人工智能(AGI)迈进。